

En muchas reuniones de planificación de infraestructuras se está dando una conversación que se parece a esto: “La IA agencial va a cambiar la relación CPU/GPU. Así que, simplemente necesitamos añadir más CPU a nuestros servidores GPU, ¿verdad?”.
Suena lógico. Pero ahí es donde mucha gente se equivoca.
El cambio de la IA basada en chatbots a la IA agente no se trata solo de añadir algunas CPU más a la misma arquitectura de rack con gran cantidad de GPU. Es mucho más complejo. Se trata de un cambio estructural en la arquitectura de los centros de datos. La IA agente está impulsando la demanda de racks completamente nuevos de servidores de CPU que se ubican junto a la infraestructura de GPU y se ejecutan para dar soporte al trabajo de todos estos agentes.
Para los líderes de TI empresariales, todo esto encierra una lección: la IA agencial reescribe la ecuación de la infraestructura de IA.
En AMD, hemos estado siguiendo de cerca este cambio. Si bien anteriormente habíamos previsto un mercado de CPU para servidores con un crecimiento anual del 18%, el aumento estructural en los requisitos de computación impulsado por los agentes modifica las cifras. Ahora esperamos que el mercado total potencial para las CPU de servidores crezca a más del 35% anual, alcanzando más de 120 mil millones de dólares para 2030.
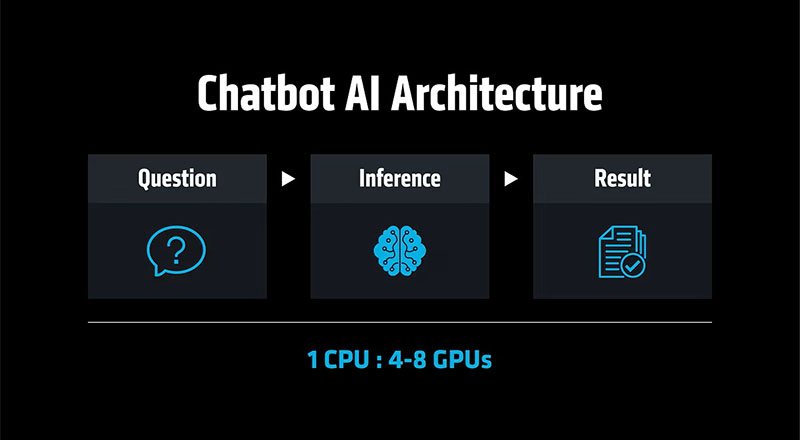
La primera ola: la IA de los chatbots se basaba principalmente en respuestas modeladas
La primera oleada de IA generativa se basó en un patrón bastante simple. El usuario formulaba una pregunta; la aplicación enviaba una solicitud a un modelo; el modelo generaba una respuesta; y la aplicación la devolvía.
Esa arquitectura impulsó naturalmente los diseños centrados en GPU. En esas implementaciones, una CPU actuaba como nodo principal de un servidor con entre cuatro y ocho GPU. La CPU del nodo principal se encargaba de la planificación, la entrada/salida y la administración del sistema, mientras que las GPU realizaban los cálculos complejos.
La IA agencial no es solo «chat con herramientas»
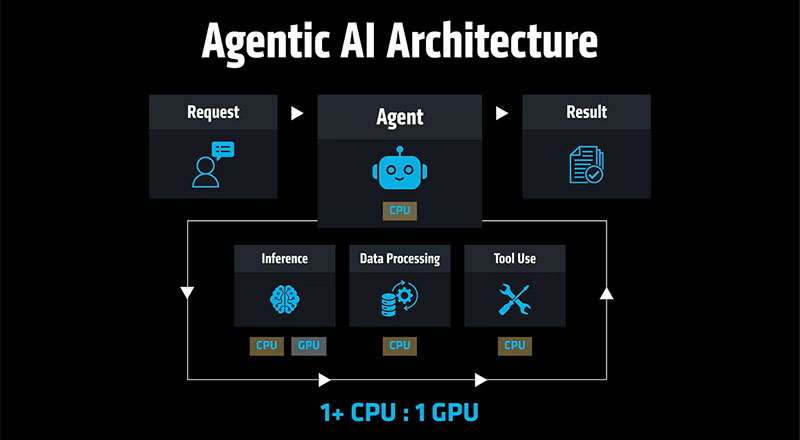
Nos encontramos en los albores de la era de la IA agente. En ella, la estructura de la carga de trabajo cambia por completo. En lugar de responder a una sola pregunta, un agente divide un objetivo en pasos, decide qué hacer a continuación, llama a múltiples modelos, consulta bases de datos, se conecta con API, ejecuta aplicaciones empresariales, verifica permisos, recupera memoria, valida la salida y luego repite el proceso. Se trata de un perfil de infraestructura muy diferente al de la IA de chatbot que responde a preguntas.
Las GPU siguen siendo fundamentales para la ejecución de modelos, pero la carga de trabajo de producción ahora requiere un uso intensivo de la CPU. Las CPU son responsables de:
• Orquestación: Gestionar el motor que descompone las tareas complejas.
• Ejecución de agentes y llamadas a herramientas: activación de API y software empresarial heredado.
• Política y seguridad: Realizamos comprobaciones en entornos reales de cada acción autónoma.
La solución al cambio entre CPU y GPU no es simplemente «añadir más CPU».
En lugar de la anterior relación CPU-GPU de 1:4-8 con la IA de los chatbots, estamos viendo que la IA agente se está moviendo hacia una relación de 1:1 y, en algunos casos, es mayor en el lado de la CPU.
Aquí está lo importante: esto no se logra simplemente añadiendo más CPU a un conjunto de GPU. Se logra agregando una capa de cómputo de CPU de nuevo diseño.
Para los líderes de TI empresariales, aquí es donde su planificación debe evolucionar.
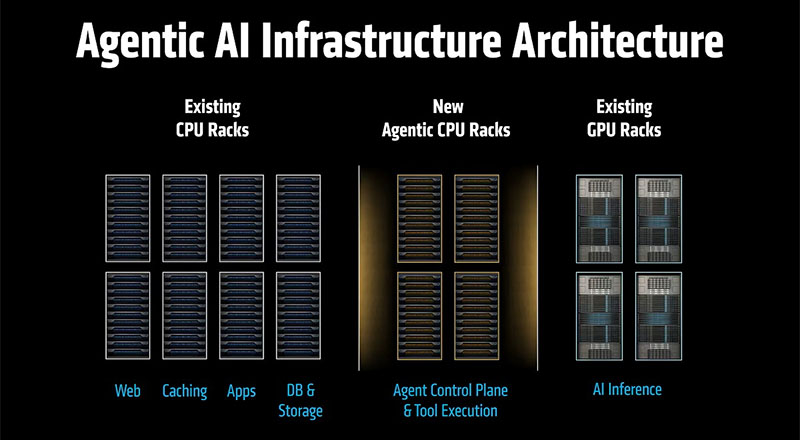
El sistema de IA preferido para los próximos años no será una única «caja de IA». Se parecerá más a un sistema distribuido. Contará con racks de GPU para el cálculo intensivo de modelos, redes rápidas y una pila de software que permita mantenerlo todo observable, seguro y eficiente. Y tendrá racks de CPU con capacidad de gestión para la orquestación, el procesamiento de datos y la ejecución de herramientas.
En este punto, una arquitectura equilibrada será más importante que nunca. Si la capa de CPU es insuficiente, las GPU se quedan en espera. Si la red se descuida, los agentes se bloquean. Si la ruta de datos es compleja, la latencia aumenta. Si la capa de orquestación no está diseñada para la concurrencia, aumentan los costos y la complejidad.
¿Dónde encaja AMD?
Los procesadores AMD EPYC™ ofrecen a los clientes una gama de opciones de CPU optimizadas para las distintas fases del flujo de trabajo de IA, desde el liderazgo en alta frecuencia para tareas que requieren baja latencia hasta el liderazgo en núcleos de alta densidad para un rendimiento escalable. Seguimos ampliando este liderazgo con nuestra hoja de ruta actual, que incluye los productos «Venice», los cuales expandirán aún más la gama de CPU optimizadas para IA. En definitiva, proporcionamos el silicio especializado necesario para equipar cada rack de su centro de datos (y cada instancia de computación en su entorno de nube) con exactamente lo que necesita.
Consejos prácticos para líderes de TI
Lo diré de nuevo: la IA con capacidad de gestión de agentes está cambiando la ecuación de la infraestructura.
Mi petición a los responsables de la toma de decisiones de TI en las empresas: a medida que la IA con agentes pasa de la fase piloto a la producción, no dimensionen la infraestructura como si simplemente estuvieran añadiendo un chatbot a su empresa. Dimensionenla como si estuvieran incorporando una nueva clase de fuerza laboral digital, una que necesita planificar, actuar, verificar, recuperar información, utilizar herramientas y ejecutar flujos de trabajo durante todo el día.
Esto implica planificar una mayor capacidad de CPU de la que sugerían las primeras estimaciones de IA. Significa ir más allá del servidor GPU y considerar los racks, las redes, el software y el equilibrio operativo. En la era de la inteligencia artificial, el rendimiento no dependerá de un solo procesador que lo haga todo, sino de la arquitectura adecuada: CPU y GPU trabajando juntas para que la IA pase de responder preguntas a actuar.